Convolutional Neural Networks for NLP Classification
今天的论文来自于较老的几篇论文,使用CNN进行文本分类。
CNN最早被成功运用在图像处理中,因为图像的位置不变性、大小不变性使得CNN处理图像再适合不过。而将CNN运用于文本分类流行于2014-2015年左右,大概处于在NLP被RNN统治的前几年,因此虽然这些论文年代已经相对比较久远,但仍然值得一读,因为通过对这些论文的阅读,还能大致了解为什么CNN在NLP领域也能取得成功,CNN在NLP领域存在什么问题,以及在NLP领域CNN的使用是如何慢慢过渡到RNN的使用的。
Convolutional Neural Networks for Sentence Classification
这是发表在EMNLP 2014上的一篇short paper,这篇文章使用多个filter组成的CNN构建了一个分类模型。
模型结构
模型的结构直接用论文中的一张图就可以比较清楚的说明。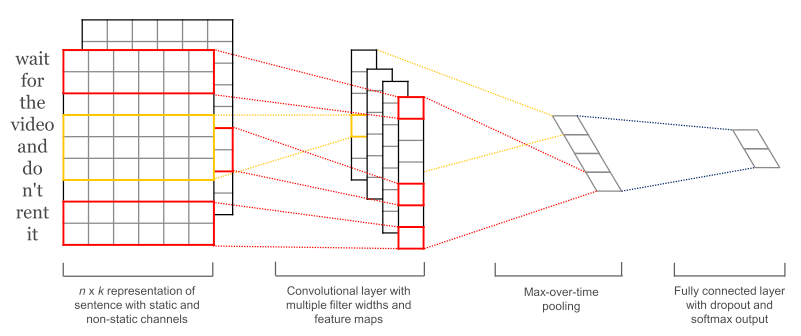
输入的文本经过word2vec的embedding生成长度为$k$的向量后,成为一个$l \times k$的矩阵$\mathbf{x}_{1;n}=\mathbf{x}_1 \oplus \mathbf{x}_2 \oplus … \oplus \mathbf{x}_l$。然后使用宽度为$k$,长度为$3,4,5$的卷积核(filter)对这个矩阵进行扫描。
因为卷积核的宽度和embedding的维度相同,因此相当于卷积核在单词的方向上滑动(sliding window)。对于每个单独的卷积核$h \times k$,将生成对应 $l-h+1$ 个feature。
然后做一个max pooling
这个$\hat c$就是当前这个卷积核的特征了。这样做的一个好处是,可以使用不同长度的卷积核,因为每个卷积核最后都会生成一个$1 \times 1$的特征,因此可以把这些特征拼起来,再接一个softmax就可以用做分类了。
实验
作者在实际训练的时候使用在全连接层使用了dropout,另外还加了l2正则。实际训练的时候使用长度分别为3, 4, 5的卷积核,每个长度100个。使用的数据集基本上都是情感分类相关的,有:MR(影评,2分类)、SST-1(情感,5分类)、SST-2(情感,2分类)、Subj(主观性,2分类)、TREC(问题分类,6分类)、CR(商品评价,2分类)、MPQA(观点评价,2分类)。
此外,作者尝试使用了不同的预训练模型组合,包括:不使用预训练模型,随机初始化embedding、使用静态的预训练模型、训练时微调的预训练模型、以及同时结合静态和微调的预训练模型(使用两个通道,一个通道静态,一个通道微调,卷积的时候直接相加)。最终的结论是,微调的比不微调的要好一点,但是两者结合的和微调的差不多。
总结
我认为这篇文章最有价值的贡献就在于如何把CNN运用到NLP中,作者使用了sliding window的方法,保持宽度不变的同时使用了不同长度的卷积核,通过一个max pooling可以把这些卷积核的特征拼在一起,十分巧妙。max pooling看起来是最常用的压缩特征的方法,也有人用average pooling的,但是看起来还是max pooling效果最好?我一个不太理解的地方在于,为啥max pooling是最有效的呢,如果正数和负数是对称的,那我如果我用min pooling,每次取最小的那个有没有效果呢?
Character-level convolutional networks for text classification
这篇文章发表在NIPS 2015上。这篇文章和上面Kim这篇非常类似,最大的区别在于Kim使用了word2vec作为预训练模型,而这篇直接使用one-hot把文本作为字符编码,直接将字符编码的矩阵作为输入,不使用任何预训练模型。另外一点不同的是,这篇文章使用了多层的卷积层,而Kim这篇是单层的。
模型结构
模型结构非常类似。作者使用维度为70的one-hot向量编码句子中的每一个字符,然后把它们全部拼起来。作者选取前1014个字符,截断多余的。拼成一个$1014 \times 70$的矩阵。接下来对这个矩阵进行卷积操作,方法应该也是类似的,卷积核在矩阵上进行一维方向上的滑动。在前2层,使用高度为7的卷积核,每个卷积层后面接一个高度为3的max-pooling。后面4层分别使用高度为3的卷积核,并且最后一层再接一个max-pooling。因此对于输入长度为1014,前6层后的长度变为$(((1014-7+1)/3-7+1)/3-2-2-2-2)/3=34$,矩阵大小变为$34 \times 70$,然后拍平成一维的向量,就可以接后面的全连接层了。
实验结果
作者对训练数据做了增强,具体就是使用一些同义词替换原来的句子,丰富训练数据。训练数据也使用了大规模的文本语料,包括AG新闻分类、雅虎新闻分类等等。最后实验发现,在数据规模没那么大的时候(~50万),n-gram+TFIDF的表现还是最后,但在数据规模更大的情况下(~100万-300万),作者提出的模型效果更好。
总结
这篇文章不借助任何先验知识(预训练模型),但能比使用word2vec的CNN模型表现更好(相差不大),一方面是由于这篇文章的使用多层的CNN结构,学习特征的能力更强。另一方面,使用字符级别的特征可以不去在意文本本身的语义信息,从而更好地处理通用的文本序列,甚至可以是用户自己定义的某种语言,相比借助预训练模型的网络具有更好地泛化能力。
Recurrent convolutional neural networks for text classification
这篇文章来自于AAAI 2015。作者认为,现有的CNN模型受限于固定长度的窗口大小,无法很好的学习上下文,这会导致诸如一词多义,长依赖语义等问题没有办法被现有的模型学习到,为了解决这个问题,作者自己提出来了一种称之为RCNN的结构,虽然这篇也含有CNN,但实际上并非广义上的CNN,而是作者自己提出来的一种模型结构。
模型结构
本文的模型结构如下图所示。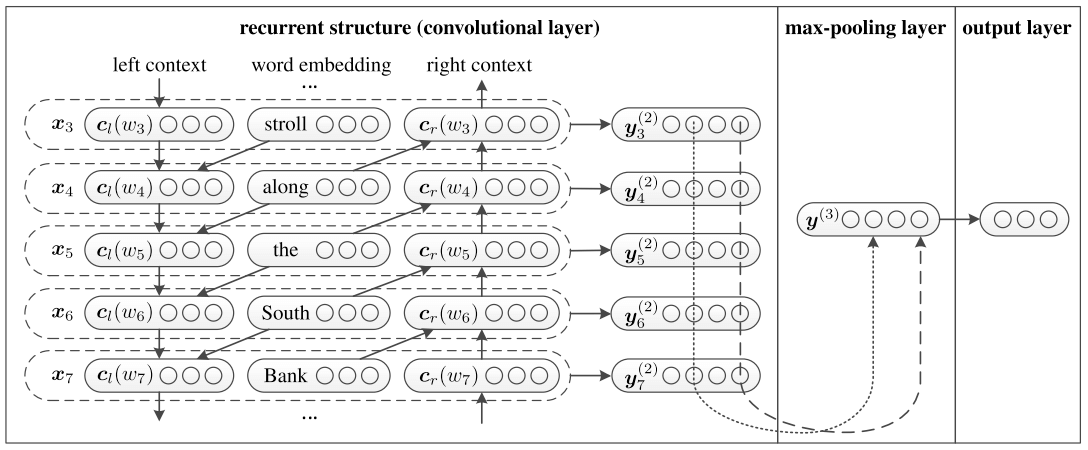
作者使用$\mathbf{c}_l(w_i)$和$\mathbf{c}_r(w_i)$来分别表示当前单词的上文和下文,$\mathbf{e}(w_i)$则表示单词本身的embedding。这样$\mathbf{c}_l(w_i)$和$\mathbf{c}_r(w_i)$的就可以用如下公式计算。
这样$\mathbf{c}_l(w_i)$就包含了所有$w_i$左边(上文)单词的语义信息,$\mathbf{c}_r(w_i)$就包含了所有$w_i$右边(下文)单词的语义信息,这三个向量每个向量的维度都是50,接下来只要把$\mathbf{c}_l(w_i)$, $\mathbf{e}(w_i)$, $\mathbf{c}_r(w_i)$三个向量拼起来,就可以作为每个单词的语义表示了。
后面的套路就和大部分文章差不多了,每个$\mathbf{x}_i$先接一个线性层,然后把$\mathbf{x}_i$拼起来后用一次max-pooling,最后再接一层全连接+softmax就结束了。
论文的其他部分没什么特别的创新之处,在此就不赘述了。
总结
这篇文章提出了一种新颖的RCNN结构,相比CNN,RCNN可以捕获更多的上下文语义。而相比RecursiveNN,它可以通过max-pooling筛选更有价值的信息,并且构造模型的复杂度更低。这篇文章算是同时结合了RNN和CNN的优点,但我认为主要还是依靠RNN。这篇文章也算是比较早的使用RNN进行文本分类的论文之一了,之后几年就开始有大量的运用RNN/LSTM到NLP的论文涌现。
最后总结
总的来说,CNN在NLP领域确实取得了一定程度的成功,这一方面归功于深度学习中强大的计算学习能力,另一方面归功于CNN本身,将图像处理中正方形的卷积核稍作改动,使用滑动窗口的方法将卷积核沿着句子中的单词方向上滑动,这一做法本身非常符合直觉,因此确实取得了一定的效果。然而,我们也能看到CNN在NLP领域中存在的问题,比如正是由于滑动窗口的方法固定了窗口大小,使得模型效果很容易受到其影响,另外这一方法使得模型无法很好地学习单词上下文的信息,这些问题反过来也限制了模型的性能。
参考文献
- Kim, Y. (2014). Convolutional neural networks for sentence classification. EMNLP 2014 - 2014 Conference on Empirical Methods in Natural Language Processing, Proceedings of the Conference, 1746–1751. https://doi.org/10.3115/v1/d14-1181
- Zhang, X., Zhao, J., & Lecun, Y. (2015). Character-level convolutional networks for text classification. Advances in Neural Information Processing Systems, 2015-Janua, 649–657. Neural information processing systems foundation.
- Lai, S., Xu, L., Liu, K., & Zhao, J. (2015). Recurrent convolutional neural networks for text classification. Proceedings of the Twenty-Ninth AAAI Conference on Artificial Intelligence.
推荐阅读
Convolutional Neural Networks for NLP Classification